表題の件、教えてください。
ウェブスクレイピングするサイトのHTMLが添付の写真の場合、駐車台数の「4台」のみを取り出すことは可能なのでしょうか。他の項目で<td>ダグがたくさんあるので、駐車台数に絞って情報をスクレイピングすることは難しいでしょうか?
ーーーーーーーーーーーーーーーー
page_url = "https://petlife.asia/hospital/12888/"
r = requests.get(page_url)
soup = BeautifulSoup(r.text, features="html.parser")
td_tags = soup.find_all("td", class_="parking")
ではもちろんダメでした。
よろしくお願いします。


No.2ベストアンサー
- 回答日時:
> Htmlに問題ありなんですね。
> このまま試行錯誤を続けてもできないものはできないのでしょうか、、
いや、やろうと思えば出来ますよ。「この一件に関して言えば」です。
ただ、何故プログラムを書くのか。自動化が目的ですよね。
言い換えると、「ルールに則って書かれてるから」解析が可能なんだけど、「ルールに則って書かれてないモノ」にアドホックに対応したとして、じゃあ、その書いたプログラムは普遍性があるのか、ってぇと違うわけでしょう。
Webページにまたもやデータが追加されるかもしれない。そうなったら今「アドホックに対応して書いたプログラム」は将来的に破綻します。それは貴方にとって嬉しい事なのか。多分違うんですよね。
んで、ぶっちゃけ、何故に皆やりたがる割には最終的にWebスクレイピングが人気が無いのか、ってぇとこれが理由なんですよ(笑)。HTMLって人がビルダとかCSS使ってるにせよ「ブラウザに表示できりゃエエや」ってテキトーに書いてるケースがあるんで、「ルール違反」があって、ルール違反がある以上、「理屈通りに解析出来ない」ケースが出てくる。他人が作ったモノ(HTML)には信用がおけない。これに尽きるんです。
余談: yak shaving で人生の問題の80%が説明できる問題
http://0xcc.net/blog/archives/000196.html
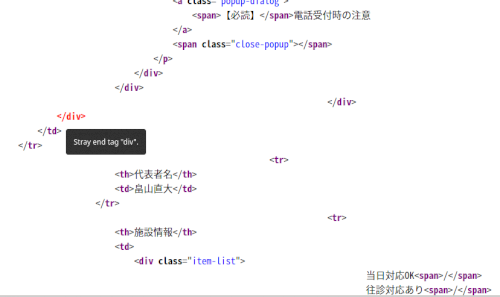
仮にこのページがキチンとHTMLで書かれてたとしたら、方策としては<table class="b-info">を取り出して、その中身の<th>タグをキー、<td>タグを値とした辞書(dictionary)データを作ります。そうすれば理論的には"駐車場台数"をキーとしたら"4台"が取り出される筈なんですけどねぇ。直近のタグを使ってデータを取り出そうと何個か試験してみたんですが、全部「余計なtd」のせいで、その後ろのデータを食えないんですよねぇ。
-
-

- 0
- 件
-
No.1
- 回答日時:
> td_tags = soup.find_all("td", class_="parking")
駐車場の台数を調べたい、っつってもtdタグにparkingってのは存在しないんじゃないですか?
存在しないものを指定してもしょーがない。
それ以前に、このWebページ、Html記述が「間違ってる」気がします。
そのためにページのパーズが上手く行ってないんじゃないか・・・。
</div>が一つ多い為に、それ以降の「施設情報」が上手く読み取れないんだよなぁ・・・・。
このページの作成元に連絡入れた方が良いかも(笑)。ブラウザが「緩く」判断してくれるお陰で正常に表示はされていますが・・・・・・。
-
-
- 0
- 件
-
この回答へのお礼
お礼日時:2020/08/22 11:00
ご回答ありがとうございました。
ご指摘の通り、ないものを指定してしまっていました。
Htmlに問題ありなんですね。
このまま試行錯誤を続けてもできないものはできないのでしょうか、、
お探しのQ&Aが見つからない時は、教えて!gooで質問しましょう!
関連するカテゴリからQ&Aを探す
おすすめ情報
デイリーランキングこのカテゴリの人気デイリーQ&Aランキング
-
プログラム言語
-
vba 正規表現について教えてく...
-
vba クリップボードクリアにつ...
-
pythonでのローカルファイルか...
-
if関数とは?
-
今のプログラミング言語
-
ネットワークフォルダの中身を...
-
プログラミングについて
-
画像生成AIのプロンプトの作り...
-
⚠️至急です!⚠️ Yahoo!知恵袋の...
-
自作scratch アニメの商用利用
-
プログラミング言語のバージョ...
-
uwscでPauseキーが押されたら、...
-
Python... 環境設定 初心者です...
-
Geminiフォーム 画像生成で 人...
-
数学、プログラミング、物理、...
-
pip --versionがエラーになる
-
pythonの実行に関する質問
-
OS入ってる機器のソフト・アプ...
-
CSVファイルの複数行削除
マンスリーランキングこのカテゴリの人気マンスリーQ&Aランキング
-
ウェブスクレイピング Python B...
-
変動する
-
JSONで文字列が長い時
-
Application.ScreenUpdating = ...
-
formで特定のinputを送信しない...
-
メモリをアドレスを直接指定し...
-
セレクトメニューで2つの項目...
-
「*:*」って何を意味するのでし...
-
シェルスクリプトで、空白(ス...
-
実行時エラー 3020の対策
-
<SELECT>タグの折り返し
-
ACCESS テキストボックスを隙...
-
16進の10進変換について
-
vbaでxmlからNodeListでデータ...
-
VB6で、長い時間かかる処理...
-
文字の横にプルダウンを表示さ...
-
c言語 16進数の2進数への変換
-
実行中の変数の中身をイミディ...
-
I2C接続のLCDディスプレイを使う
-
【至急!!!】python言語で本を見...
おすすめ情報
