A 回答 (3件)
- 最新から表示
- 回答順に表示
No.3
- 回答日時:
#1さんの指摘のとおり確率密度分布になっていないのに加えて、A/Bの分布なのかf(A)/f(B)の分布なのかわかりませんね。
どれを求めたいのかはわかりませんが、A/Bの分布を求めてみたので書いておきます。
確率変数A, Bはパラメータλの指数分布の[p, q]の範囲(ただし0 ≦ p < q)を残し切断した分布にiidで従うとします。
パラメータλ(>0)の指数分布の確率密度関数が
Exp(x) = λexp(-λx) (0 ≦ x < ∞)
= 0 (x < 0)
であることから、A, Bの確率密度関数が
f(x) = (λ/(exp(-λp)-exp(-λq)))exp(-λx) (p ≦ x ≦ q)
= 0 (その他)
であることが容易にわかります。
確率変数A, Bを
U = A/B
V = B
と変換すると
dadb = |v|dudv
で、確率密度が0とならない部分は
p/q ≦ u ≦ q/p
p/u ≦ v ≦ q (p/q ≦ u ≦ 1のとき)
p ≦ v ≦ q/u (1 < u ≦ q/pのとき)
であるので、求める確率密度関数は
u < p/qのとき 0
p/q ≦ u ≦ 1のとき
∫_p^{q/p} f(uv)f(v)dv = (1/(exp(-λp)-exp(-λq))^2)(G(λq(u+1))-G(λp(u+1)/u))/(u+1)^2
1 < u ≦ q/pのとき
∫_{p/q}^q f(uv)f(v)dv = (1/(exp(-λp)-exp(-λq))^2)(G(λqt(u+1)/u)-G(λp(u+1)))/(u+1)^2
u > q/pのとき 0
となります。ここでG(x)は形状母数が2で尺度母数が1のガンマ分布の分布関数です。
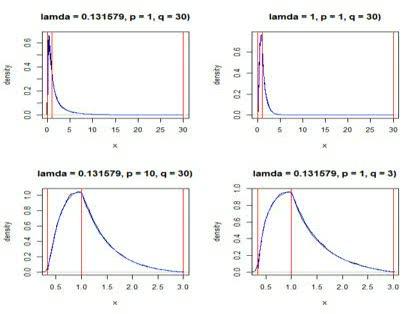
実際にパラメータを
p = 1
q = 30
λ = 1/7.6
と他3とおり設定して分布を描いてみました。
青い線が理論的な分布、黒い線がシミュレーションによる分布、赤い線は実現値の上限、下限および1を示しています。
シミュレーションはA, Bに従う乱数を10万組発生させて、カーネル密度により分布を描きました。
結果は見てのとおりほとんど一致しました。
グラフの作成は統計解析ソフトR 2.14.0により下記のコードを使いました。
(エラー処理はしてません)
# 理論的な確率密度関数
myPdf <- function(x, lamda, p, q)
{
results <- numeric(length(x))
tmp <- 1 / (exp(-lamda * p) - exp(-lamda * q))^2
flag <- x >= p / q & x <= 1
results [flag] <- tmp * (pgamma(lamda * q * (x[flag] + 1), 2) - pgamma(lamda * p * (x[flag] + 1) / x[flag], 2)) / (x[flag] + 1)^2
flag <- x > 1 & x <= q / p
results [flag] <- tmp * (pgamma(lamda * q * (x[flag] + 1) / x[flag], 2) - pgamma(lamda * p * (x[flag] + 1), 2)) / (x[flag] + 1)^2
return(results)
}
# 乱数の発生
myRnd <- function(n, lamda, p, q)
{
results <- numeric(n)
i = 0
while (i < n) {
tmp <- rexp(2, lamda)
if (sum(tmp >= p & tmp <= q) == 2) {
i <- i + 1
results[i] <- tmp[1] / tmp[2]
}
}
return(results)
}
# シミュレーションの実施と分布の描画
sim <- function(n = 100000, lamda, p, q)
{
title <- sprintf("lamda = %g, p = %g, q = %g)", lamda, p, q)
x <- myRnd(n, lamda, p, q)
plot(density(x), xlim = c(p / q, q / p), main = "", xlab = "", ylab = "", xaxt = "n", yaxt = "n")
par(new = T)
plot(function(x) myPdf(x, lamda, p, q), xlim = c(p / q, q / p), ylab = "density", col = "blue", main= title)
abline(v = p / q, col = "red")
abline(v = 1, col = "red")
abline(v = q / p, col = "red")
}
par(mfrow = c(2, 2))
sim(100000, 1 / 7.6, 1, 30)
sim(100000, 1, 1, 30)
sim(100000, 1 / 7.6, 10, 30)
sim(100000, 1 / 7.6, 1, 3)
par(mfrow = c(1, 1))
-
-

- 0
- 件
-
No.2
- 回答日時:
和と積の確率密度は聞くけど、商は??と言う程度の者です。
興味が合って検索したら下のHPが見つかりました。
http://wkouw.web.fc2.com/MYPEDIA_math/Word_sekin …
商の確率密度の式の積分を和に置換えて数値計算できるのではないでしょうか。
nも30と少なく、幸いXもYもゼロでは無いのでX/Yも無限大には成らないし。
昔三重積分(和)をベーシックで計算した経験から、マクロで計算できるとは
思いますが。残念ながらマクロは不案内です。
確率密度ですから、104.605で割ってΣf(x)=1と成るように規格化して置いた方が
無難です。
-
-
- 0
- 件
-
お探しのQ&Aが見つからない時は、教えて!gooで質問しましょう!
似たような質問が見つかりました
- 数学 以下の数学の問題を教えてください。 確率変数Xは標準正規分布N(0、1)に確率変数Yは平均3のポアソ 3 2022/12/02 19:13
- 統計学 確率変数XとYは独立で一様分布U(0,1)に従うとき、E(X+3)、E((X+Y)^2)、XとYの同 1 2022/07/28 22:34
- 統計学 確率変数XとYは独立で一様分布U(0,1)に従うとき、E(X+3)、E((X+Y)^2)、XとYの同 2 2022/07/29 00:25
- 数学 確率について ①Xが実数値をとる確率変数で、f(x)=0(x<=-1),1/4x+1/4 (-1<= 2 2022/06/20 18:44
- 数学 X_1,…X,nを独立で同じ確率分布に従う確率変数列とする。 Xmin=min{X_1,…,Xn}, 5 2023/01/13 22:00
- 統計学 確率変数XとYは独立で一様分布U(0,1)に従うとき、(1)E(X+1)、(2)E((X+Y)^2) 2 2022/07/30 09:39
- 統計学 Xが[0,1]を台に持つ連続一様分布に従う確率変数とするとき、Y=X^2/3が従う確率分布の確率密度 4 2022/11/15 13:36
- 数学 確率について 事象Aが起こる確率が0.25である独立行列において、試行回数を5回とした時Aの起こった 2 2022/06/06 19:46
- 数学 確率変数 Zが正規分布N(5,4^2)に従うとき、確率P(7=<X=<9)を求めると、【??】である 5 2022/09/11 18:53
- 数学 確率変数 X,Y が独立で、ともに指数分布 e(1) に従う。 X+Y=Z であるとき、X,Z の同 1 2023/07/28 11:03
このQ&Aを見た人はこんなQ&Aも見ています



おすすめ情報
このQ&Aを見た人がよく見るQ&A
デイリーランキングこのカテゴリの人気デイリーQ&Aランキング
-
累積分布関数とは?
-
正規分布を割り算した分布
-
ノイズとポアソン分布?
-
相対合成不確かさの計算
-
X,Yは正規分布(0,1)に従う...
-
乱数から正の数のみ、または負...
-
場合の数
-
対数分布則とはどういう意味か...
-
ワイブル分布の確率密度関数と...
-
f分布の関係式とt分布の関係式
-
基本統計量の「ひずみ」と「と...
-
素数の規則性って
-
一方が正規分布と、もう片方は...
-
確率変数Xが自由度1のカイ2乗検...
-
「t分布が自由度に従うのはなぜ...
-
統計学でいうRSD%とは何ですか。
-
標準偏差バーをグラフに入れた...
-
統計学における有効数字につい...
-
統計でいう「n」は、何の略な...
-
標準偏差
マンスリーランキングこのカテゴリの人気マンスリーQ&Aランキング
おすすめ情報
